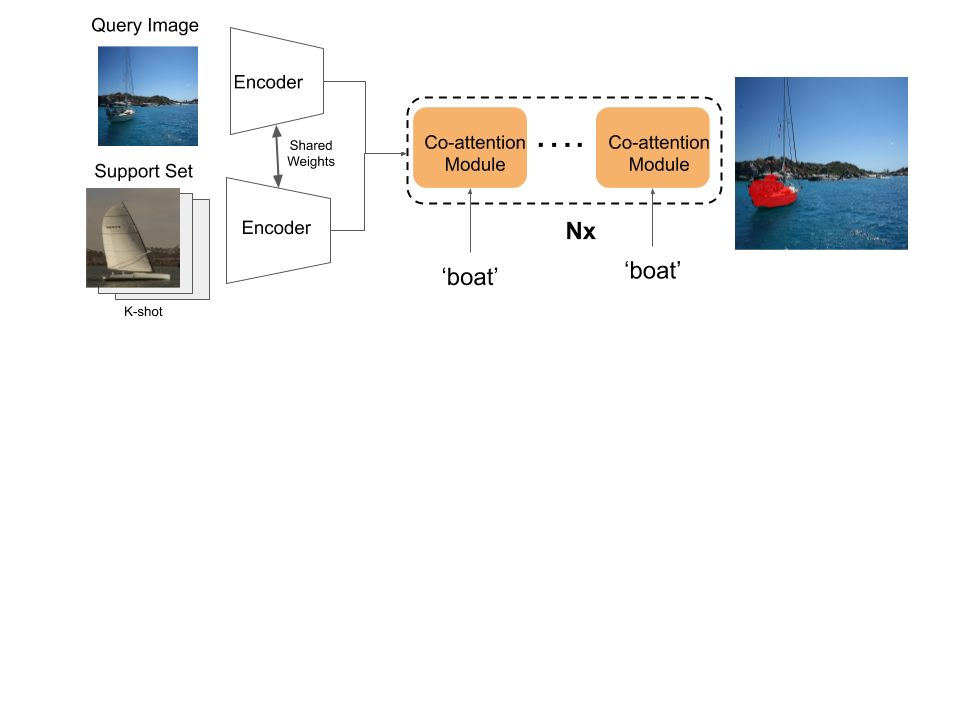
Few Shot Learning, the ability to learn from few labeled samples, is a vital step in robot manipulation. In order for robots to operate in dynamic and unstructured environments, they need to learn novel objects on the fly from few samples. The current object recognition methods using convolutional networks are based on supervised learning with large-scale datasets such as ImageNet, with hundreds or thousands labeled examples. However, even with large-scale datasets they remain limited in multiple aspects, not all objects in our lives are within the 1000 labels provided in ImageNet.
As humans we can hold the object and check it from different viewpoints and try to interact with it to learn more about the object. Thus the robot should be able to teach itself from the few samples for the different object viewpoints. If we are aiming as well at human centered artificial intelligence, a natural step is to teach robots about their environment through human robot interaction. A human teacher can show the object with different poses and verbally instruct the robot on what it is and how it can be used. A further step is combine that with the ability to learn from large-scale web data about that object.