I will be writing in this post about few-shot segmentation which I just had a recent work in ICCV'19. So what started me to be interested in that topic was two things: (1) The fact that I come from a developing country. (2) And since it could be a mean for robotics to operate in unstructured environments.
I originally come from Egypt, so I understand very well that we neither have computational resources nor the resources to collect enormous data as big tech companies do. I recently read this interesting article which I related to so much about algorithmic colonialism, quoting it"data is the new oil". I concluded from the start of my PhD when studying deep learning it's not going to be a fair game if it stays this way, which got me interested in both few-shot learning and domain adaptation. In few-shot learning you can learn from few labelled data, and with unsupervised domain adaptation you can learn from synthetic data and simulation environments. I personally would encourage more research on few-shot learning, self supervised learning and domain adaptation for people working in developing countries. Of course almost all developing countries main problem is a corrupt government and ruler, few-shot learning is not gonna solve that but that's out of my hands currently.
The other reason that got me into learning from limited labelled data is the goal to have robots operating in unstructured environments. Quoting the recent work from Google AI "A robot deployed in the real world is likely to encounter a number of objects it has never seen before" [1]. Quoting another work in few-shot segmentation "A rough estimate of the number of different objects on the Earth falls in the range of 500,000 to 700,000, following the total number of nouns in the English language"[2]. It seems to me critical to get robots to incrementally learn about novel objects from few labelled data and not just rely on large-scale datasets. So I will be explaining in the first part of the article:
- Few-shot Segmentation setup.
- Briefly introduce the related work.
In the second part I will introduce the work we were doing in details.
Few-shot Segmentation (FSS) Setup
The few-shot segmentation dataset used in the literature is PASCAL-5i[3] which is based on PASCAL-VOC. It has 20 classes split into 4 folds each with 5 classes. The training data is for the 15 classes from outside the fold, while the test data is for the 5 classes from the fold. The following Table shows the folds and corresponding classes. In the current literature the setup proposed is 1-way K-shot where we try to learn the segmentation of 1 novel class in a query image based on the provided support set with K shot. In order to compare with OSLSM who proposed the setup 1000 samples are randomly chosen for both query image and support set during the few-shot test.
| Fold | Classes |
|---|---|
| 0 | aeroplane, bicycle, boat, bottle |
| 1 | bus, car, cat, chair, cow |
| 2 | dining table, dog, horse, motorbike, person |
| 3 | potted plant, sheep, sofa, train, tv/monitor |
A newer dataset was just released which is called FSS-1000 [2]. It has 1000 object classes with pixel-wise segmentation masks. The dataset contains various objects outside PASCAL VOC which makes it even more interesting to experiment with.

Previous Work on FSS
The first attempt to few-shot segmentation was OSLSM [3] which proposed the PASCAL-5i setup and compared their proposed method against different baselines.
Baselines
OSLSM [3] introduced 3 baselines:
- Finetuning: simply finetuning the final layers using the support set.
- Siamese: trained a siamese network for performing pixel verification similar to [4] but on the pixel level, then during inference each pixel is labelled based on the nearest neighbour.
- Base Classifiers: they pretrain FCN32s[5] on 16 classes (15 classes outside the fold + background). Then use the features to train simple classifiers which were logistic regression and nearest neighbour.
Parameter Prediction
OSLSM (One-shot Learning for Semantic Segmentation) [3] proposed a 2-branch method where one branch predicts the segmentation parameters based on the image-label pair of the support set as input. The other branch then learns the segmentation for the query using the predicted parameters as the following figure. The model is meta-trained on PASCAL-5i training data with 15 classes. In case you're wondering what the term meta-training means it means that we sample from the training data both support set (few labelled samples as training data) and query image (to test on). Then train on the support set and query image as input to simulate the few-shot setting. In case you're interested to learn more about meta-learning check this ICML tutorial
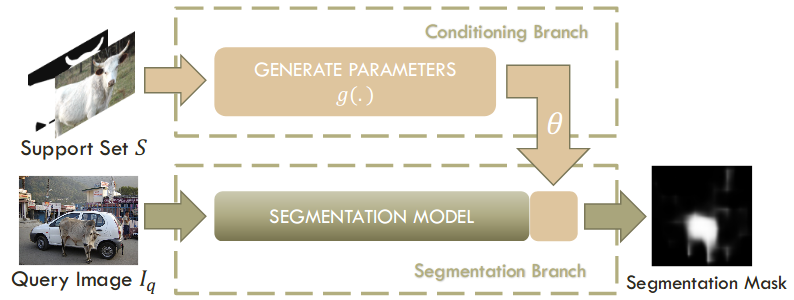
Conditional FCN
Co-FCN (Conditional FCN) [6] proposed a two-branch method as well with the second branch acting as a conditioning branch. Unlike OSLSM it concatenates with the annotations to the features instead of the input image. It is mainly designed to work with sparse annotations, and they consider (K,P)-shot learning setting where P is the number of pixels annotated. They consider the tasks as a binary (Fg-Bg) segmentation problem which is 1-way segmentation.

The conditioning branch tries to extract a task representation from the sparsely annotated support set using a task representation encoder. The encoder relies on extracting visual features of the support set image, then maps sparse annotations to masks in the feature space and performs elementwise multiplication. The annotations to mask mapping is performed by interpolation. Finally it performs average pooling. The segmentation branch then concatenates the output task representation after being spatially tiled and the visual features of the query image to infer the segmentation. The overal model is meta-trained on PASCAL-5i.
Prototype Learning
PL+Seg [7] inspires from the work or ptotypical networks [8], it uses a two-branch method as well where the second branch is responsible for learning prototypes as in the following figure.
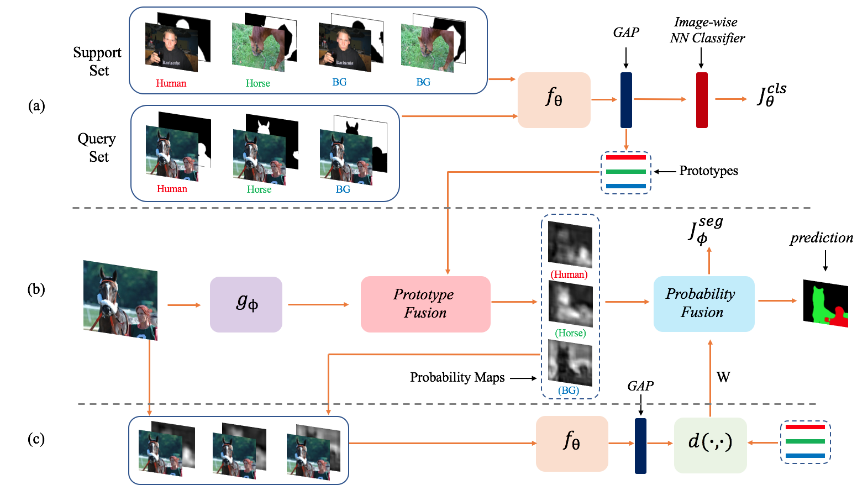
Class Agnostic Segmentation
CANet [9] is a new approach just recently got published in CVPR 2019, it mainly relies on two modules the dense comparison module (DCM) and the iterative optimization module (IOM).
The DCM module uses masked average pooling over the support set to extract the embeddings corresponding to the support set novel object then concatenates it with the query image features.
The DCM output is further refined using the IOM module which takes: (a) the features from the DCM, and (b) the predicted mask from the previous iteration. The initial iteration takes the DCM output directly. It incorporates the predicted mask in a residual form following this equation:
Where \(x\) is the output features, \(y_{t-1}\) is the predicted mask from lasst iteration, \(M_t\) is output from residual block.
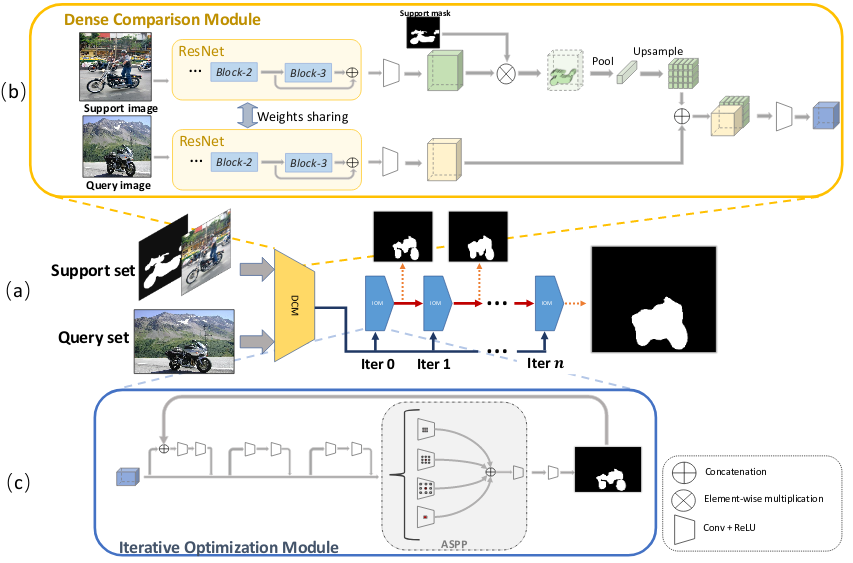
Learning from my Mistakes
I did a lot of mistakes for preparing that setup previously so I thought to share my previous mistakes to help others not to go through them.
- I had to ensure that I read the randomly sampled files from OSLSM exactly as is for the support set and query image to ensure fair comparison. Since I initially had my own loader that would sample support set and query images and it turned out to give minor difference to what OSLSM was utilizing. A better way from the start is to use multiple runs, each with 1000 samples drawn, but using different random seeds and average all runs.
- Also to ensure no overlap between the training and test data for both the classes and the images itself while using SBD extra data. I realized it would be better to use train_aug.txt that I am providing in the repo for such a goal.
- In order to compare against OSLSM it is also important to use the same image size 500x500 as they provided in their setting.
- During the training or meta-training stage based on your method, the validation should not be performed on the fold classes. They should never be introduced to the model before the few-shot test. I have seen encounters where some unintentionally will be saving the best checkpoint based on validating on the fold classes which can be problematic.
- Another thing that was pretty confusing in the literature how to evaluate the mean intersection over union. There are two approaches one that was used in [6][7], which basically considers the task as a binary segmentation problem and computes the average of IoU for background and foreground classes. The other method that was used by [3] is to average IoU over the 5 classes in the fold, although the method uses binary labels but it assigns the IoU to the correct class label from the fold classes. I personally prefer the second method since it does not incorporate the background class which will dominate the IoU metric and will seem high although the effective IoU is much lower.
If anyone has other encounters that you found others or myself doing please give feedback. It’s always great to improve and learn from our mistakes.
Finally if you are a MSc/PhD student that originally came from a developing country remember it is equally important that we help back students there. It is equally important too if we are able to drive research that can be conducted in developing nations with the limited resources we have. I definitely recommend this anime “The Promised Neverland” the hero is a girl that did not just want to save herself she insisted on taking everyone on board, it will motivate you better 😂.

References
[1] Pirk, Sören, et al. "Online Object Representations with Contrastive Learning." arXiv preprint arXiv:1906.04312 (2019).
[2] Wei, Tianhan, et al. "FSS-1000: A 1000-Class Dataset for Few-Shot Segmentation." arXiv preprint arXiv:1907.12347 (2019).
[3] Shaban, Amirreza, et al. "One-shot learning for semantic segmentation." arXiv preprint arXiv:1709.03410 (2017).
[4] Koch, Gregory, Richard Zemel, and Ruslan Salakhutdinov. "Siamese neural networks for one-shot image recognition." ICML deep learning workshop. Vol. 2. 2015.
[5] Long, Jonathan, Evan Shelhamer, and Trevor Darrell. "Fully convolutional networks for semantic segmentation." Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
[6] Rakelly, Kate, et al. "Few-shot segmentation propagation with guided networks." arXiv preprint arXiv:1806.07373 (2018).
[7] Dong, Nanqing, and Eric Xing. "Few-Shot Semantic Segmentation with Prototype Learning." BMVC. Vol. 1. 2018.
[8] Snell, Jake, Kevin Swersky, and Richard Zemel. "Prototypical networks for few-shot learning." Advances in Neural Information Processing Systems. 2017.
[9] Zhang, Chi, et al. "CANet: Class-Agnostic Segmentation Networks with Iterative Refinement and Attentive Few-Shot Learning." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.