In robotics especially navigation in unstructured environments and manipulation you are often faced with continuously changing environment for the robot to operate in. Since training deep networks rely heavily on large-scale labelled datasets, its not often very clear how one can utilize deep learning and expect it to scale well within this changing environment. Well, people started to realize that we have lots of training data in synthetic environments and we can easily create more. So why not use them to train deep networks then deploy on real data, or use a mix of relatively smaller labelled real data and abundant synthetic data. The problem with such methods is that there is a gap between synthetic and real domains.
Some work has addressed this domain shift on the feature level during the training of tasks such as semantic segmentation like the recent work from LSD-Seg in CVPR’18 [19]. Others are working on learning a mapping from synthetic to real domains and generating real images from either synthetic images or from semantic labels. Image-to-Image translation is the problem of translating images from one domain to another. This is not a post to exhaustively go through different work in that area. It’s rather a summary of 3 papers from Nvidia that are relevant to this topic. Since my work is focused on robot learning I found the work super exciting, and valuable to that area and hope other robtics researchers can benefit from that too.
The 3 main work I will be summarizing is:
- Pix2Pix HD [1]
- Vid2Vid [2]
- UNIT [3]
This post does not detail variational auto-encoders nor generative adversarial networks. In order to learn about them you can check these nice tutorials:
- GANs Tutorial NIPS’16 (PDF, Video)
- Detailed derivation to relate GAN loss and Jenson Shannon Divergence. (Blog Post)
- VAE Explained nicely here (Blog Post)
In the area of Image-to-Image translation supervised methods rely on paired images from the two domains during the training. While unsupervised methods work with unpaired images. The first two papers are under supervised methods, while the third one is an unsupervised method.
Datasets
I will first list couple of datasets or simulation environments that can help researchers collect data to test synthetic to real adaptation. Then detail the methods listed above.
Autonomous driving:
| Synthetic | Real | Simulation |
|---|---|---|
| GTA [4][5] | Cityscapes[8] | AirSim [12] |
| Synthia [6] | Mapillary[10] | CARLA [13] |
| Virtual KITTI [7] | KITTI [9] | |
| Apolloscape [11] |
Indoor robot navigation and manipulation:
| Synthetic | Real | Simulation |
|---|---|---|
| ShapeNet [14] | ADE20k [15] | Thor [17] |
| NYU RGB-D [16] | House 3D [18] | |
| IVOS [20] |
You will notice I am inclined toward semantic segmentation datasets cause that is relevant when it comes to robotics scene understanding. I am not inclined toward pure end2end methods without auxiliary losses. I also dont think its enough to have sole object detection for example for robot learning. Segmenting the contours for the different objects to aid grasping, and further segmenting the affordances (associated actions) for the different parts in an object is a must.
Pix2Pix HD
Paper Code
It is a conditional GAN method that focuses on generating high resolution images and has two main contributions:
- Multiscale generator and disciminator
- Adversarial loss based on feature matching
A coarse to fine generator with 2 sub-networks (\(G_1\) at resolution 1024 x 512, \(G_2\) at resolution 2048x1024). Each generator is composed of:
- A convolutional front-end \(G^F\).
- A set of residual blocks \(G^R\).
- A transposed convolutional backend \(G^B\).
A multi-scale descriminator is used as well by building a pyramid of 3 scales, where the real/generated images are downsampled by factor 2 and 4.
The GAN loss is further improved by incorporating a feature-matching loss based on the discriminator. By extracting features on multiple layers from the discriminator network for both synthesized and real images. This helps the training of the generator as it enforces it to generate statistics similar to the real data.
\(L_{FM}(G, D_k) = E_{(s, x)} [\sum^{T}_{i=1} \frac{1}{N_i} \lVert D^{(i)}_k(s, x) - D^{(i)}_k(s, G(s)) \lVert_1\)] Where:
- \(T\) : total number of layers.
- \(N_i\) : number of elements in each layer.
- \(D^{(i)}_k\) : the ith layer of the discriminator at scale k.
- \(s\) : semantic label map.
- \(x\) : corresponding real photo.
- \(G(s)\) : corresponding generated image.
Vid2Vid
Paper Code
The work in video-to-video synthesis [2] is a conditional GAN method for video generation. It is similar to Image-to-Image translation methods such as Pix2Pix, but instead of generating still images it generates coherent video frames by modeling the temporal dynamics. So summarizing how it works:
- Problem Setup:
- Source Images: \(s_1^T = \{ s_1, s_2, ..., s_T \}\) [Semantic Segmentation Masks]
- Target Images: \(x_1^T = \{ x_1, x_2, ..., x_T \}\) [Real Images]
- Predicted Images: \(\tilde{x}_1^T = \{ \tilde{x}_1, \tilde{x}_2, ..., \tilde{x}_T \}\)
- Vid2Vid Method:
- Sequential Generator: The current generated frame depends on 3 things:
- The current source image.
- The past L source images (L=2 in his case).
- The past L generated images. (Relying on this specifically is what makes the video generation coherent rather than generating each frame independantly)
- Based on this a feedforward network is trained \(F(\tilde{x}^{t-1}_{t-L}, s^t_{t-L})\) to predict \(\tilde{x}_t\).
\(F\) is modelled based on the warping of the previously generated frame with the computed optical flow :
\[F(\tilde{x}^{t-1}_{t-L}, s^t_{t-L}) = \tilde{w}_{t-1}(\tilde{x}_{t-1})\]- Note that this warping would be able to help the generation of most of the scene, yet some new objects and scenery would be entering the field of view, others will be occluded. So it is important to model both :
\(F(\tilde{x}^{t-1}_{t-L}, s^t_{t-L}) = (1-\tilde{m}_t) \circ \tilde{w}_{t-1}(\tilde{x}_{t-1}) + \tilde{m}_t \circ \tilde{h}_t\)
- To detail each part in the above equation:
- \(\tilde{w}_{t-1}\) : is the warping function based on computed optical flow from \(\tilde{x}_{t-1}\) to \(\tilde{x}_t\). Note that this flow is computed from the previous L source images (segmentation masks) + previous L generated images.
- \(\tilde{m}_t\) : is a mask that determines the areas that are new or occluded and needs to be hallucinated from scratch.
- \(\tilde{h}_t\) : The hallucinated image from scratch.
- Discriminator: There are 2 discriminators, the image discriminator \(D_I\) and the video discriminator \(D_V\). \(D_I\) ensures that each generated frame would resemble a real image. While \(D_V\) ensures the consecutive frames resemble a real video with coherent temporal dynamics.
- Objective : The overall objective is still a minimax game where the \(F\) is the generator and two discriminators for image and video \(D_I\) and \(D_V\). Along with the flow estimation loss \(L_w(F)\). \(\min_F {(\max_{D_I}{L_I (F, D_I) + \max_{D_V}{L_V(F, D_V)} })} + \lambda_w L_w(F)\)
- Sequential Generator: The current generated frame depends on 3 things:
The video demo of the work is super cool:
The above setup relies on paired training data, which means if you need to train the method for synthetic to real video generation you will need a paired training data. Which is not so feasible to do, although VKITTI and KITTI raw data can be used. However, it is very small training data to work with. Thats why I will talk next about the unpaired setup.
They show that their method can be utilized to generate simulated images for testing autonomous driving in NeurIPS’18 which is pretty cool. Although the main bottleneck here how to ensure diversity in your generated images? As it will generate images similar to distribution of cityscapes or the dataset trained upon.
UNIT
Paper Code
Unsupervised Image-to-Image Translation works on unpaired set of images without the need for paired set of images. The main idea for that work is on learning a shared latent space.
- Problem Setup:
- \(X_1\), \(X_2\) : two image domains (e.g: Synthetic and Real)
- \(E_1\), \(E_2\): Encoders for the two domains that map to a shared latent space
- \(G_1\), \(G_2\): Generators for the two domains.
- By ensuring that:
- \[E_1(x_1) = E_2(x_2) = z\]
- \(x_1 = G_1(z)\), \(x_2 = G_2(z)\) A shared latent space is learned that can be used to translate images from one domain to another
- The translation function between the 2 domains will be a composition of both encoders and generators: \(x_2 = F_{1 \rightarrow 2} (x_1) = G_2( E_1(x_1))\) \(x_1 = F_{2 \rightarrow 1} (x_2) = G_1( E_2(x_2))\)
- Goal:
- Learn \(F_{1 \rightarrow 2}\), \(F_{2 \rightarrow 1}\)
- While maintaining the cycle consistency constraint: \(x_1 = F_{2 \rightarrow 1}(F_{1 \rightarrow 2}( x_1))\)
- UNIT Method:
- The following Figure shows the framework used.
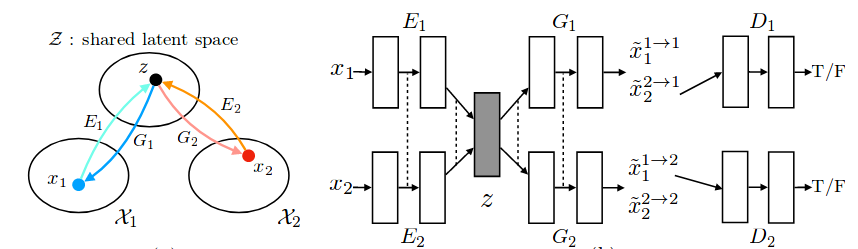
- A VAE is constructed from the encoder-generator pair for each domain.
- \(E_1\) maps from input image \(x_1\) to the shared latent space \(z\), while \(G_1\) reconstructs the image
- \(E_2\), \(G_2\) behave similarly.
- \(D_1\) and \(D_2\) are the discriminators responsible for classifying the generated images as real/fake for the GAN loss.
- This results in 6 subnetworks as shown in the Figure from the paper, the final layers of the 2 encoders \(E_1\), \(E_2\) have shared weights that extract the high-level representation. The first few layers of the 2 generators \(G_1\), \(G_2\) are shared as well.
-
It is important to note that during training there are 4 types of recononstructed output to ensure the shared latent space:
\(G_2(z_2 \sim q_2(z_2|x_2) )\) : That is the reconstructed image from generator \(G_2\) that operates on latent space \(z\) sampled from the output of the encoder \(E_2\). It reconstructs the image to its domain \(X_2\).
\(G_1(z_1 \sim q_1(z_1|x_1) )\) : That is the reconstructed image from generator \(G_1\) that operates on latent space \(z\) sampled from the output of the encoder \(E_1\). It reconstructs the image to its domain \(X_1\).
\(G_2(z_1 \sim q_1(z_1|x_1) )\) : That is the reconstructed image from generator \(G_2\) that operates on latent space \(z\) sampled from the output of the encoder \(E_1\). It translates to the other domain \(X_2\)
\(G_1(z_2 \sim q_2(z_2|x_2) )\) : That is the reconstructed image from generator \(G_1\) that operates on latent space \(z\) sampled from the output of the encoder \(E_2\). It translates to the other domain \(X_1\) - Objective has 3 types of losses without going in details:
- VAE loss for (\(E_1\), \(G_1\)) and (\(E_2\), \(G_2\))
- GAN loss for (\(E_1\), \(G_2\), \(D_2\)) and (\(E_2\), \(G_1\), \(D_1\)), note that adversarial training is for the translated images.
- Cycle Consistency Loss to ensure the constraint we mentioned above is met: \(x_1 = F_{2 \rightarrow 1}(F_{1 \rightarrow 2}( x_1))\)
So whats next?
- It will be interesting to see the unpaired version of video-to-video synthesis without relying on semantic labels to generate the data.
- I am also curios whether optical flow is the best fit to utilize on its own for video-to-video synthesis. What other modalities can be incorporated? How specifically to incorporate the geometry of the scene from LIDAR as an example to improve the generated images.
- I am still wondering how to generate multiple images from the same semantic label to ensure diversity in your training data? Since the paired setting relies heavily on supervised training if its trainined on cityscapes it will just generate images similar to cityscapes distribution. Not only that but how to control the generated scene elements to vary even if similar to cityscapes distribution.
References
[1] Wang, Ting-Chun, et al. “High-resolution image synthesis and semantic manipulation with conditional gans.” arXiv preprint arXiv:1711.11585 (2017).
[2] Wang, Ting-Chun, et al. “Video-to-Video Synthesis.” arXiv preprint arXiv:1808.06601 (2018).
[3] Liu, Ming-Yu, Thomas Breuel, and Jan Kautz. “Unsupervised image-to-image translation networks.” Advances in Neural Information Processing Systems. 2017.
[4] Richter, Stephan R., Zeeshan Hayder, and Vladlen Koltun. “Playing for benchmarks.” International conference on computer vision (ICCV). Vol. 2. 2017.
[5] Richter, Stephan R., et al. “Playing for data: Ground truth from computer games.” European Conference on Computer Vision. Springer, Cham, 2016.
[6] Ros, German, et al. “The synthia dataset: A large collection of synthetic images for semantic segmentation of urban scenes.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
[7] Gaidon, Adrien, et al. “Virtual worlds as proxy for multi-object tracking analysis.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
[8] Cordts, Marius, et al. “The cityscapes dataset for semantic urban scene understanding.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
[9] Geiger, Andreas, et al. “Vision meets robotics: The KITTI dataset.” The International Journal of Robotics Research 32.11 (2013): 1231-1237.
[10] Neuhold, Gerhard, et al. “The Mapillary Vistas Dataset for Semantic Understanding of Street Scenes.” ICCV. 2017.
[11] Huang, Xinyu, et al. “The ApolloScape Dataset for Autonomous Driving.” arXiv preprint arXiv:1803.06184 (2018).
[12] Shah, Shital, et al. “Airsim: High-fidelity visual and physical simulation for autonomous vehicles.” Field and service robotics. Springer, Cham, 2018.
[13] Dosovitskiy, Alexey, et al. “CARLA: An open urban driving simulator.” arXiv preprint arXiv:1711.03938 (2017).
[14] Chang, Angel X., et al. “Shapenet: An information-rich 3d model repository.” arXiv preprint arXiv:1512.03012 (2015).
[15] Zhou, Bolei, et al. “Semantic understanding of scenes through the ADE20K dataset.” arXiv preprint arXiv:1608.05442 (2016).
[16] Silberman, Nathan, et al. “Indoor segmentation and support inference from rgbd images.” European Conference on Computer Vision. Springer, Berlin, Heidelberg, 2012.
[17] http://vuchallenge.org/thor.html
[18] Das, Abhishek, et al. “Embodied question answering.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Vol. 5. 2018.
[19] Sankaranarayanan, Swami, et al. “Learning from Synthetic Data: Addressing Domain Shift for Semantic Segmentation.” arXiv preprint arXiv:1711.06969 (2017).
[20] Siam, Mennatullah, et al. “Video Segmentation using Teacher-Student Adaptation in a Human Robot Interaction (HRI) Setting.” arXiv preprint arXiv:1810.07733 (2018).