In this post I will explain co-attention mechanism in both video object segmentation (VOS)[1] and few-shot object segmentation(FSS)[2].
In points I will mainly explain:
- COSNet model for video object segmentation [1]. [paper, Code]
- Vanilla Co-attention[1].
- Coattention with Visual and Semantic Embeddings for few-shot object segmentation [2]. [ paper, Code to be released April]
Co-attention in Video Object Segmentation
In CVPR 2019 a paper in unsupervised video object segmentation[1] discussed an interesting solution for the problem using co-attention which I will go through some of its details. But let me first introduce the task of unsupervised video object segmentation. The main target in unsupervised video object segmentation is to segment the primary object, visually salient and motion salient object, in video sequences. DAVIS benchmark is the most widely used benchmark in this field[3]. One way to define the primary object in a video sequence is through these two assumptions:
- Visually salient in the frame (Local constraint).
- Frequently appearing in the video sequence (Global constraint).
Check this video sequence to elaborate better on the importance of the second assumption specifially, over which the whole method intuition is built upon. You will see that visually salient objects per frame assumption solely, will not be able to easily capture the boy and bicycle in the highlighted frames in red.
This is where the second assumption is important it can be easily achieved by training a siamese co-attention network with pairs of sampled frames in a video sequence, then during the inference phase use multiple reference images. Note that even COSNet suffers from failures in occlusions but it can handle when faced with background clutter and even if at some frames the boy/bike are not as visually salient as before.
A detailed view of COSNet model is shown in this Figure:
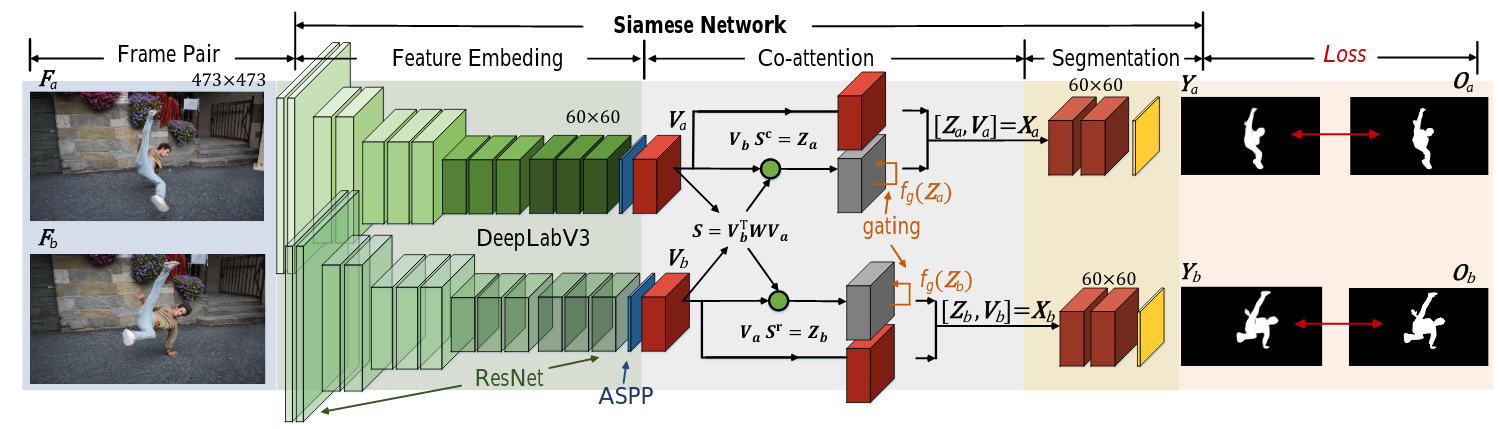
The COSNet model is trained on sampled pairs of video frames within the sequence using cross entropy loss for the segmentation of both images. During inference the model takes multiple reference frames instead of one to guide the segmentation of the query frame. Thus, COSNet will be able to correlate different video frames and segment better the frequently ocurring object in the video sequence.
Co-attention Mechanism in Details
In this section we go through the details of only the vanilla co-attention described in the paper. we are provided with two frames \(I_a\), \(I_b\):
1- First we start by extracting features for the two frames \(V_a, V_b\), then flattening them from CxWxH into CxWH tensors.
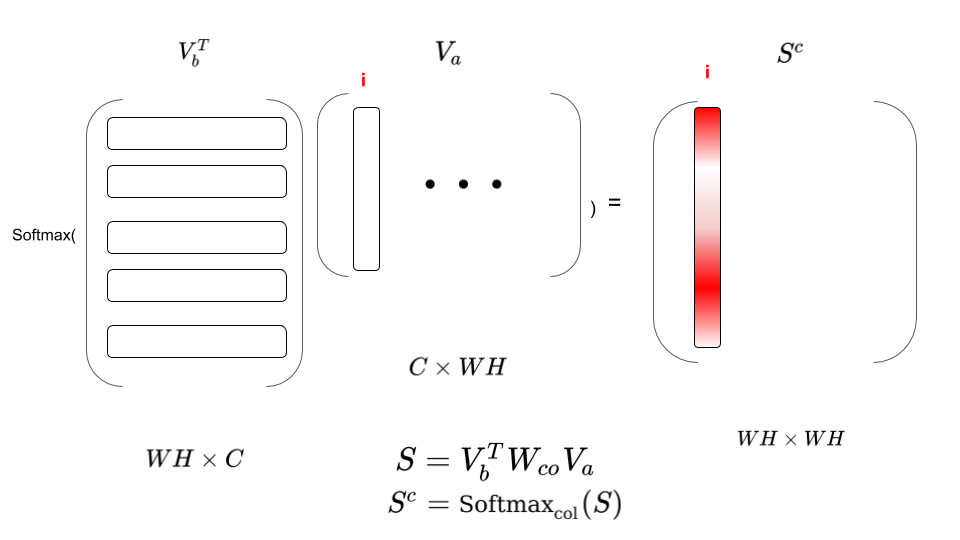
2- Then compute pixel-to-pixel affinity \(S=V_b^TWV_a\) To better understand the affinity matrix look to this Figure, you can see that column i in \(S^c\) matrix correpsonds to the correlation among all pixels in \(V_b\) and pixel i in \(V_a\). When taking the softmax column-wise you end up with attention weights in the \(i^{th}\) column, that describe how relevant all \(V_b\) pixels to \(i^{th}\) pixel in \(V_a\).
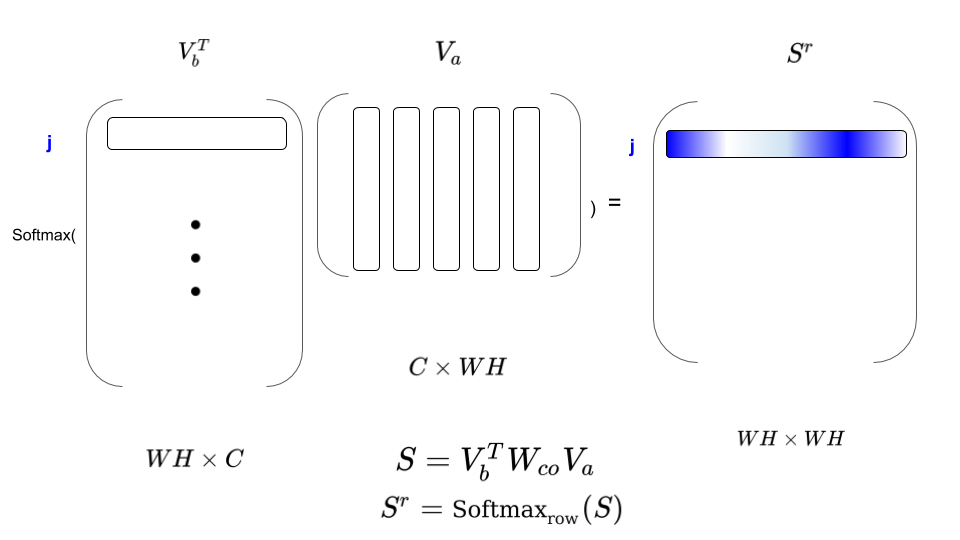
3- Now look into this Figure and you will notice that taking row-wise softmax \(S^r\) will relate all pixels in \(V_a\) to pixel j in \(V_b\). Hence the name of co-attention, since you are considering a dual attention among both frames.
4- Well since we already have the attention weights we can use it to construct what the author calls attention summaries: \(Z_a = V_b S^c\), \(Z_b = V_a S^r\) What does this exactly mean? If you look in this Figure, let’s take one example the first column \(z_a^{(1)}\):
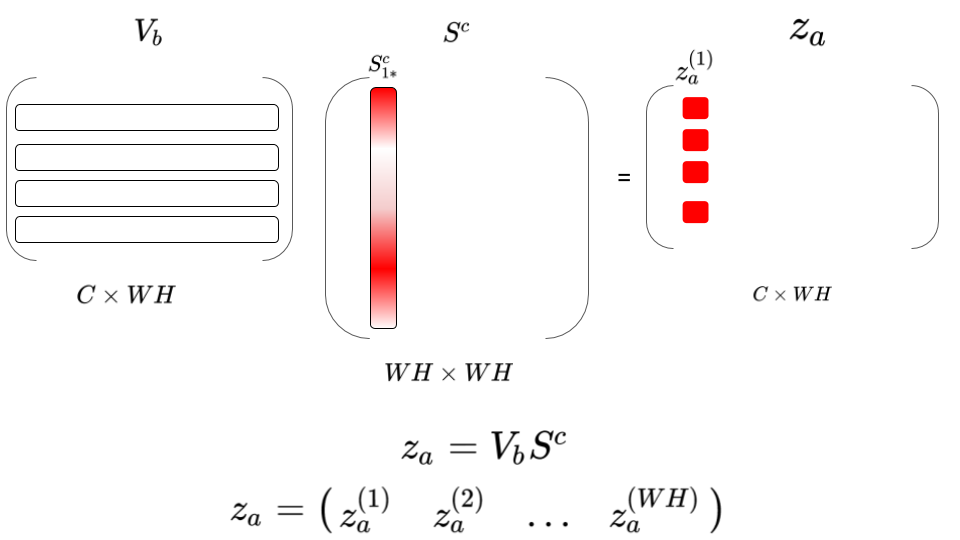
You can see that this is basically weighted summation of all pixels in \(V_b\) based on how relevant is it to first pixel in \(V_a\), using \(S^c_{1*}\), hence the name attention summaries.
5- Finally let’s do one more thing that will improve the signal to differentiate it from noise due to cluttered background or occlusions. We can learn a gating function \(f_g(z_a) = \sigma(W_fz_a + b_f)\)
This \(f_g\) will learn [0, 1] value per pixel to give better significance to the commmon foreground object among the frames. An elementwise multiplication \(\circ\) with the original attention summaries is performed.
\[Z_a = Z_a \circ f_g(Z_a)\]6- The exact same procedure is performed to compute \(Z_b\), the concatenation of these attention summaries with the original features \(V_a, V_b\) is used as input to the segmentation decoder.
7- During Inference when you have multiple reference you can simply average the attention summaries which will aggregate the information from different reference frames \(N\). \(Z_a = \sum\limits_{n=1}^N Z_a^n \circ f_g(Z^n_a)\)
Co-attention in FSS with Visual and Semantic Inputs
Few-shot object segmentation main goal is to segment a query image with novel classes unseen during training, with few support set images used as a training set for these novel classes. Previous literature in FSS had two main issues that we are tackling, Figures are taken from [5], [6]:
1- Most literature in FSS use a single vector representation through masked average pooling to represent the support set and use it to guide the query image. This eventually leads to lost critical information that is required when performing object segmentation where object details (different parts, ..,) is important. As shown in the Figure below in Red.
2- All previous work in FSS except one[4] requires pixel-level labels or the least bounding box labels. In our work we investigate image-level labels. As shown in the Figure below highlighted in Blue.
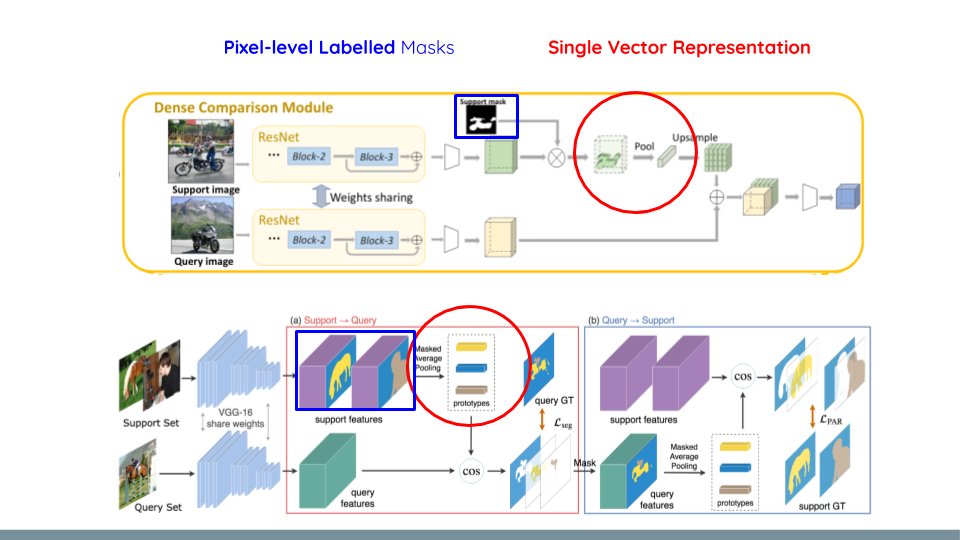
We tackle the first through leveraging the interaction among support and query images using a stacked co-attention module. While the second issue we rather use image-level labels and depend on the semantic embeddings of the class label to condition the co-attention and segmentation modules. The Figure below details our method, in our case the co-attention module computes the pixel-to-pixel affinity using query \(\tilde{V_q}\) and support set \(\tilde{V_s}\) features, which concatenate both visual and word embeddings:
\[S = \tilde{V}_s^TW_{co}\tilde{V}_q\]Similar to the above VOS method we compute both row-wise and column-wise softmax and use it to compute the attention summaries \(U_q\) and \(U_s\) as:
\[U_q = \tilde{V}_s S^c\]The same gated co-attention is performed to suppress the noise from cluttered background. We further found stacking co-attention to improve the final output. This figure shows our detailed model architecture, where our model is metatrained on sampled pairs of support and query images on the base classes with segmentation masks. During the meta-testing phase sampled pairs for novel classes are used with support set images and only image-level labels provided.
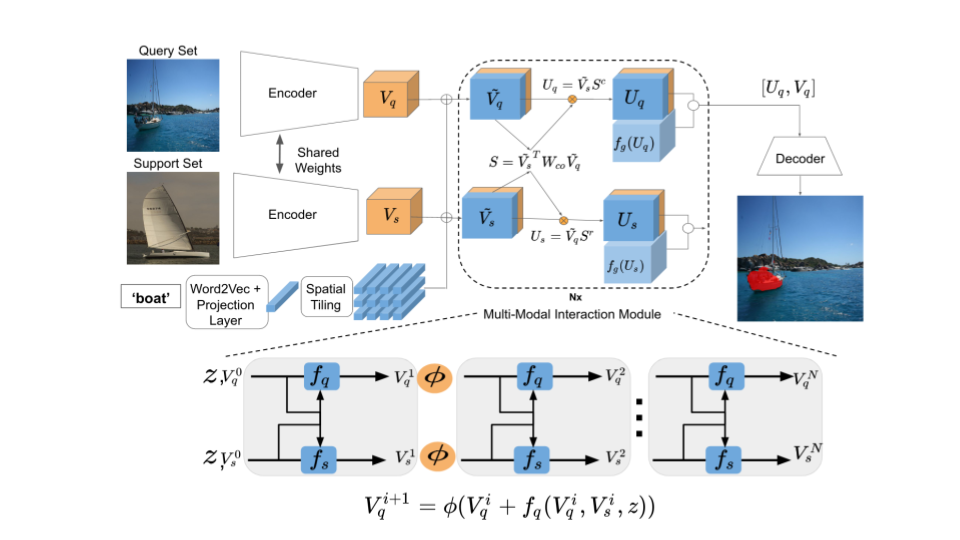
The stacked co-attention with residual connections follows these equations:
\[V_q^{i+1} = \phi(V_q^i + f_q(V_q^i, V_s^i, z))\] \[V_s^{i+1} = \phi(V_s^i + f_s(V_q^i, V_s^i, z))\]\(V_q^i\) stands for the \(i^{th}\) iteration query features, while \(V_s^i\) is the same for the support set and z is the semantic word embeddings. Initially \(V_q^0\) is the visual features extracted from ResNet-50. In the second iteration \(V_q^1 = f_q(V_q^0, V_s^0, z) + V_q^0\) , where \(f_q\) is the co-attention module with the query branch and a nonlinear projection function. Specifically \(f_q\) will perform co-attention and compute gated attention summaries \(U_q\) then concatenate with original input. A 1x1 bottleneck convolution layer is applied on these features, followed by a ReLU. This is done iteratively as shown in the above Figure of our method. The main goal from the stacked co-attention to further leverage the interaction between query and support set features, and the residual connections help improve the gradient flow to avoid vanishing gradients.

We mainly show in the above Figure that without conditioning on the semantic word embeddings, our model tends to segment base classes used during meta-training or segment other common objects between the support and query. While the semantic conditioning alleviate this problem. More results is in our paper, and our session and poster will be in IJCAI 2020 which is happening this week. We also discuss a new setup about few-shot temporal object segmentation, I would leave this to another post where we are continuing on this work for an interesting overlap between few-shot and video object segmentation directed towards autonomous driving.
References
[1] Lu, Xiankai, et al. "See more, know more: Unsupervised video object segmentation with co-attention siamese networks." Proceedings of the IEEE conference on computer vision and pattern recognition. 2019.
[2] Mennatullah Siam, Naren Doraiswamy, Boris N. Oreshkin, Hengshuai Yao, Martin Jägersand:
Weakly Supervised Few-shot Object Segmentation using Co-Attention with Visual and Semantic Embeddings. IJCAI 2020: 860-867.
[3] Perazzi, Federico, et al. "A benchmark dataset and evaluation methodology for video object segmentation." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
[4] Hasnain Raza, Mahdyar Ravanbakhsh, Tassilo Klein, and Moin Nabi. Weakly supervised oneshot segmentation. In Proceedings of the IEEE International Conference on Computer Vision Workshops, pages0–0, 2019.
[5] Zhang, Chi, et al. "Canet: Class-agnostic segmentation networks with iterative refinement and attentive few-shot learning." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
[6] Wang, Kaixin, et al. "Panet: Few-shot image semantic segmentation with prototype alignment." Proceedings of the IEEE International Conference on Computer Vision. 2019.